AI News
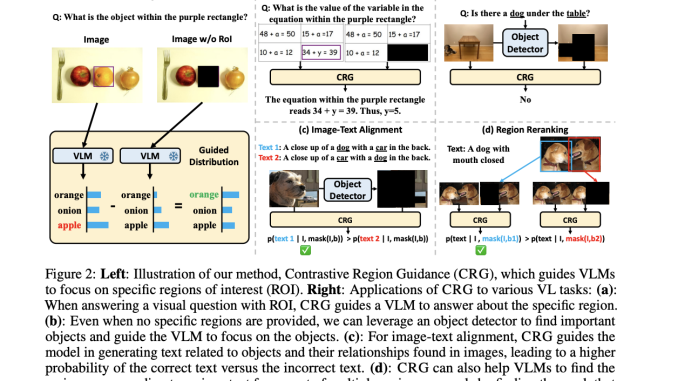
UNC-Chapel Hill Researchers Introduce Contrastive Region Guidance (CRG): A Training-Free Guidance AI Method that Enables Open-Source Vision-Language Models VLMs to Respond to Visual Prompts
Recent advancements in large vision-language models (VLMs) have shown promise in addressing multimodal tasks by combining the reasoning capabilities of large language models (LLMs) with visual encoders like ViT. However, despite their strong performance on […]







