


Large Language Models (LLMs) have demonstrated remarkable versatility in handling various language-centric applications. To extend their capabilities to multimodal inputs, Multimodal Large Language Models (MLLMs) have gained significant attention. These models are crucial for developing flexible, general-purpose assistants that can understand information from diverse modalities, including text, images, videos, and audio.
Contemporary MLLMs, such as LLaVA, typically follow a two-stage training protocol: (1) Vision-Language Alignment, where a static projector is trained to synchronize visual features with the language model’s word embedding space, enabling the LLM to understand visual content; and (2) Multimodal Instruction Tuning, where the LLM is fine-tuned on multimodal instruction data to enhance its ability to respond to varied user requests involving visual content.
Despite the critical importance of these two stages, the projector’s structure and LLM tuning strategy have been relatively underexplored. Most existing research focuses on scaling up pretraining data, instruction-following data, visual encoders, or language models. However, the learned model with static parameters may limit the potential for handling diverse multimodal tasks.
To address this limitation, researchers have proposed HyperLLaVA, a dynamic version of LLaVA that benefits from a carefully designed expert module derived from HyperNetworks, as illustrated in Figure 2. This expert module generates dynamic parameters based on the input information, enabling the model to adaptively tune both the projector and LLM layers for enhanced reasoning abilities across diverse multimodal tasks.

HyperLLaVA is trained in two steps:
In vision-language alignment, the projector is divided into static layers (the original MLP in LLaVA) and dynamic layers (visual expert). The static layers’ parameters are fixed, while the dynamic layers’ parameters are dynamically generated based on visual input. The visual expert, leveraging HyperNetworks, assists the static projector in learning a visual-specific projector that adaptively models the visual features according to visual guidance. This approach enables the projector to deliver adaptive visual tokens to the language semantic space.
In the multimodal instruction tuning stage, the LLM is equipped with a language expert, which models dynamic parameters for LLM blocks. The intermediate output of the LLM is regarded as language guidance that guides the language expert in providing an improved instruction-specific comprehension of the user’s request. By generating unique parameters for every input, the MLLM increases its flexibility, allowing it to make use of similarities between samples across datasets and avoid potential interference between samples within the same dataset.
The proposed language expert serves as a parameter-efficient fine-tuning approach for MLLMs, yielding comparable performance to the original LLaVA while enhancing the model’s ability to handle diverse multimodal tasks.
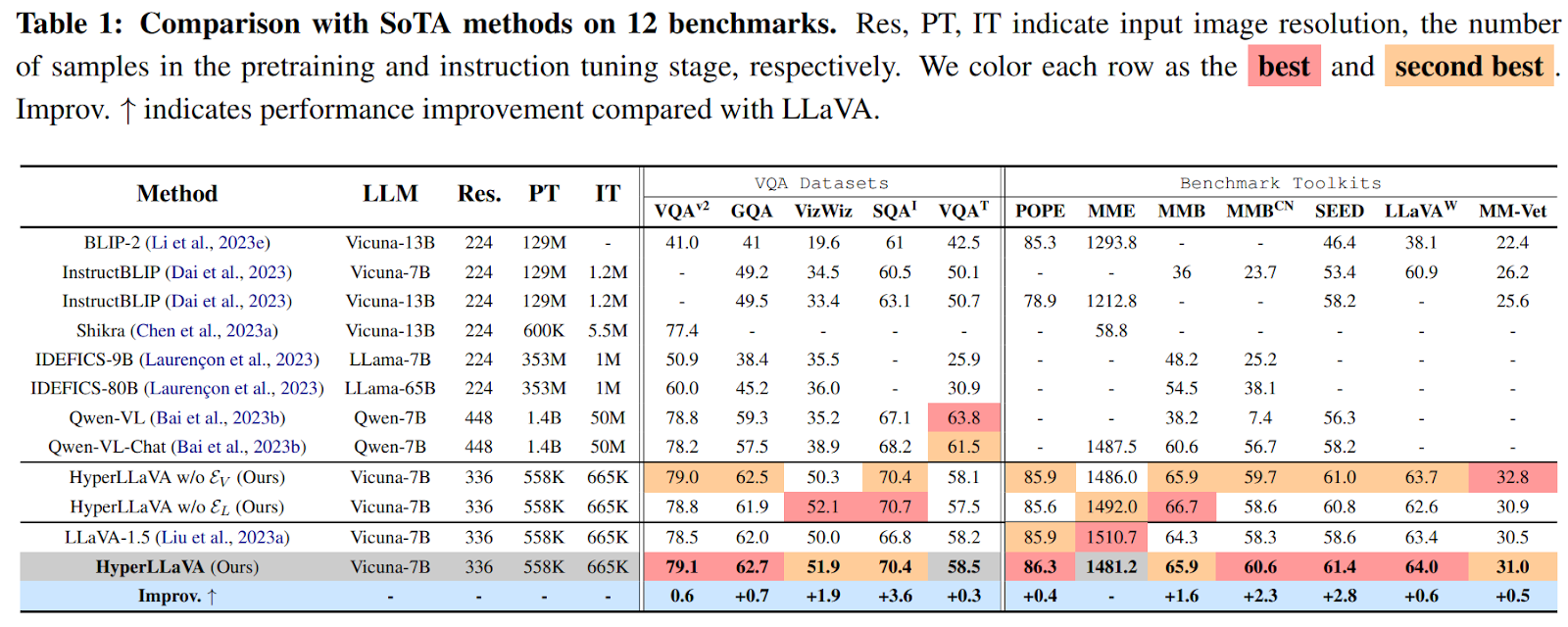
In their experiments, the researchers evaluated HyperLLaVA on multiple datasets, including five VQA datasets (VQAv2, GQA, VizWiz, SQAI, and VQAT) and seven Benchmark Toolkits (POPE, MME, MMB, MMBCN, SEED, LLaVAW, and MM-Vet). The results shown in Table 1 demonstrate that HyperLLaVA outperforms existing state-of-the-art approaches, including larger MLLMs with billions of trainable parameters, on almost all multimodal scenarios across these benchmarks. The carefully designed lightweight visual and language experts empower the static projector and LLM to facilitate different multimodal tasks, surpassing the performance of the original LLaVA across 11 out of 12 benchmarks.
In conclusion, HyperLLaVA’s innovative, dynamic tuning strategy paves the way for advancements in multimodal learning systems. By adaptively tuning projector and LLM parameters and integrating dynamic visual and language experts, the researchers have introduced a parameter-efficient methodology that surpasses existing performance benchmarks. This approach offers a new horizon for enhancing multimodal task performances through personalized, dynamic adjustments, potentially unlocking new avenues for understanding and integrating multimodal information more seamlessly.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
